

这是一篇Fuzzing测试相关论文的阅读随记,主要为了理清思路方法,文章题目是:SQUIRREL: Testing Database Management Systems with Language Validity and Coverage Feedback,2020年发表在CCS USA,一作是佐治亚理工学院的Rui Zhong,二作Yongheng Chen(是CTFer!
Abstract
Fuzzing is an increasingly popular technique for verifying software functionalities and finding security vulnerabilities. However, current mutation-based fuzzers cannot effectively test database management systems (DBMSs), which strictly check inputs for valid syntax and semantics. Generation-based testing can guarantee the syntax correctness of the inputs, but it does not utilize any feedback, like code coverage, to guide the path exploration. In this paper, we develop Sqirrel, a novel fuzzing framework that considers both language validity and coverage feedback to test DBMSs. We design an intermediate representation (IR) to maintain SQL queries in a structural and informative manner. To generate syntactically correct queries, we perform type-based mutations on IR, including statement insertion, deletion and replacement. To mitigate semantic errors, we analyze each IR to identify the logical dependencies between arguments, and generate queries that satisfy these dependencies. We evaluated Sqirrel on four popular DBMSs: SQLite, MySQL, PostgreSQL and MariaDB. Sqirrel found 51 bugs in SQLite, 7 in MySQL and 5 in MariaDB. 52 of the bugs are fixed with 12 CVEs assigned. In our experiment, Sqirrel achieves 2.4×243.9× higher semantic correctness than state-of-the-art fuzzers, and explores 2.0×-10.9× more new edges than mutation-based tools. These results show that Sqirrel is effective in finding memory errors in database management systems.
Fuzzing模糊测试 -> 一种软件测试方法,通过半随机方式的数据发送以验证软件功能和查找安全漏洞
基于mutation的fuzzer
因为DBMS严格检查输入->不可用基于generation的fuzzer
->可以保证syntax correctness
但不能利用feedback(代码覆盖率等)来引导探索路径
Squirrel
兼顾language validity和coverage feedback
Intermediate Representation -> 使得查询structural和informative
Type-based mutation -> 保证语法(syntactically)正确
Semantics-Guided Instantiation -> 保证语义(semantically)正确
Introduction
主要贡献
- Propose syntax-preserving mutation and semantics-guided instantiation to address the challenges of fuzzing DBMSs.
- Implement Squirrel, an end-to-end system that combines mutation and generation to detect DBMS bugs.
- Evaluated Squirrel on real-world DBMSs and identified 63 memory error issues. The result shows that Squirrel outperforms existing tools on finding bugs from DBMSs.
Problem Definition
1. Query Processing in DBMS
How a DBMS handles SQL queries
1) parse
- First parses the query to get its syntactic meaning
- Breaks the query into individual tokens
- Checks them against the grammar rules
2) validation
- Checks the semantic correctness of the query
3) ptimization
- 构造几个可能的查询计划 -> 确定给定查询最有效的查询计划
4) execution
- 执行 + 返回
如果1, 2阶段不满足,则不会进行到3, 4
2 Challenges of DBMS Testing
Introduce existing DBMS testing techniques & Illustrate their limitations
主要有两种DBMS测试方法:
1) model-based generation 基于模型生成
遵循精确的语法模型以生成语法正确的输入
- pros: 语法正确
- cons:
顺序扫描整个输入空间->不能有效搜索程序的状态空间
很难保证语义正确性->会被过滤
2) random mutation 随机变异
更新现有输入以生成新输入
- pros:
利用先前执行的反馈来评估生成的输入的优先级
如果反馈表明之前的输入很有趣,模糊器会将其放入队列中以进行进一步的变异
->可以有效地探索程序的状态空间 - cons:
在处理结构化输入方面效率低下(如SQL、JS)
1. 随机翻转一个 SQL 关键字的位很难产生另一个有效的关键字
2. 整个查询将在语法上变得不正确
AFL 生成的查询的验证率很低- > 语义正确很重要
3 Our Approach
Present our insight to solve this problem
1) Generating Syntax-Correct Queries
- IR->使得查询structural和informative
- 基于类型的突变来保证句法正确性
->每个语句都有语法类型,每个数据都有语义类型 - 从每个 IR 中剥离具体数据,如表名,以专注于改变骨架
2) Improving Semantic Correctness
确保语义正确是NP-hard问题
- 通过动态查询实例化 -> 保证其 SQL 模板的表现力
- 给定语法正确的 SQL 查询的骨架 -> 尝试用关系满足数据依赖图的具体操作数填充骨架
- (根据预定义的基本规则构建其数据依赖图)
Overview of Sqirrel

四个组成部分
- Translator,
- Mutator,
- Instantiator,
- SQL Fuzzer
主要流程
- 从查询队列中选一个查询I
- IR Translator将查询I翻译成IR的向量V
同时从V中剥离具体值,使其成为骨架 - Mutator生成新的向量V’(通过插入、删除、替换)
-> V’语法正确 - Instantiator对V’进行数据依赖性分析
(并构建新的数据依赖图) - Instantiator选择新的具体值填充V’,which满足数据依赖性
- 将V’转回SQL语句I‘
- 运行:
if 崩溃 -> 找到触发错误的输入
else if 触发了新的执行路径 -> 保存到队列
Intermediate Representation 中间表示(IR Translator)
SQL语句I转化成 -> IR向量V -> 改变成V’ -> 转换回SQL语句I’
- IR特点:expressive, general, simple
Syntax-Preserving Mutation 语法保留突变
Token区分
- structure:关键字 + 数学运算符
改变structure会改变查询的操作,从而触发不同的功能 - data:常量值、名称等
修改与语义相关的data可能会生成语义不正确的查询导致DBMS拒绝执行
改变structure的影响更大->剥离数据,在结构上变异
1) Structure-Data Separation
- 基本规则:用“x”替换语义数据,将常量数字更改为 1 或 1.0
- 在IR library存储不同的IR
2) Type-Based Mutation
主要是operand的变异
-> 要么修改整个IR,要么修改operand
三种变异

Insertion插入
Replacement替换
->在IR库中选择对应位置的孩子进行插入或替换
Deletion删除
验证语法正确
转回SQL语句,传入执行
if 成功执行 -> 语法正确,继续使用
else -> 丢弃
Semantics-Guided Instantiation 语义引导实例化
1) Data Dependency Inference
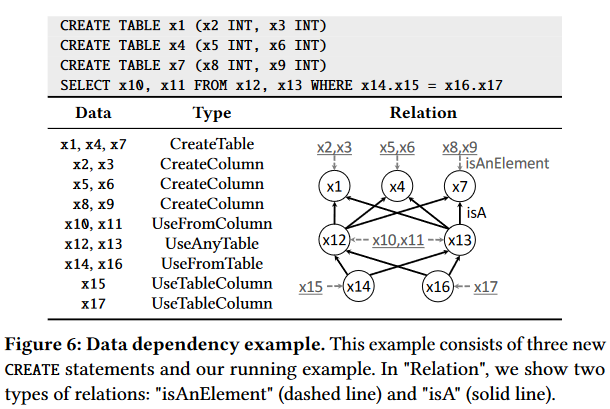
灰色线是从属关系,黑色线是对等关系
细化数据类型,遵循lifetime原则:用前创建,删后不用
关系规则是一个包含四个元素的元组(α,β,γ,S):α是关系目标,β是关系源; γ 定义关系; S 表示关系的范围
2) IR Instantiation

dataMap:跟踪具有不同类型的唯一名称
relationMap:将每个元素映射到其依赖项
验证语义正确
转回SQL语句,传入执行
if 满足依赖性,成功执行 -> 语义正确,继续使用
else -> 丢弃
if interesting -> 保存入队列
Implementation & Evaluation
此处略
Discussion
1. DBMS-Specific Logic
->针对不同DBMS系统的SQL方言语法进行设计可以提高测试效果
2. Relation-Rule Construction
人工编写关系规则 -> 自动推断(数据流分析/深度学习)
3. Collisions in Code-Coverage
扩大Bitmap的大小以缓解Collision
4. Alternative Feedback Mechanisms
code coverage VS semantics-correct queries -> 有害的代码覆盖率阻碍了语义正确查询的生成
Related Work & Conclusion
略
Summary
SQUIRREL: Testing Database Management Systems with Language Validity and Coverage Feedback这篇论文提出了一种新型的自动化测试工具Squirrel,它的主要作用是用于测试关系型数据库管理系统(DBMS)。这篇论文在2020年11月首次发表在2020 ACM SIGSAC Conference上,作者为来自宾夕法尼亚州立大学和佐治亚理工学院的Rui Zhong等6人,当前在Google学术上被引用次数为40次。
模糊测试是一种用于验证软件功能和查找软件安全漏洞的技术。但是,目前基于突变(mutation)的模糊器(fuzzer)无法有效测试会严格检查输入的语法语义正确性的数据库管理系统;基于生成(generation)的测试无法利用反馈来指导测试路径。
基于以上现状,本文整合了上述两种测试框架的优点,介绍了一种名为Sqirrel的新型模糊测试框架,用于测试数据库管理系统(DBMS),同时考虑了语言有效性和覆盖反馈。Squirrel使用中间表示(IR, Intermediate Representation)以结构化和信息化的方式维护SQL查询,并对IR进行基于类型的变异以生成语法正确的查询。它还分析每个IR以识别参数之间的逻辑依赖关系,并生成满足这些依赖关系的查询以减轻语义错误。
Squirrel的测试流程包括以下步骤:
- 生成初始查询:Sqirrel使用基于模型的生成方法生成初始查询。
- 转换为IR:Sqirrel将初始查询转换为IR,以便于后续的变异和分析。
- 变异:Sqirrel对IR进行基于类型的变异,以生成语法正确的查询。
- 依赖分析:Sqirrel分析每个IR以识别参数之间的逻辑依赖关系,并生成满足这些依赖关系的查询以减轻语义错误。
- 执行查询:Sqirrel执行生成的查询,并记录覆盖信息。
- 覆盖反馈:Sqirrel使用覆盖信息来指导下一轮变异,以提高测试效率和覆盖率。
这个流程不断迭代,直到达到预设的测试目标或者测试时间结束。
上述6个流程是对Squirrel框架的高度概括,在具体实现上仍有很多较为细节的步骤,保证了Squirrel框架的结果准确、逻辑合理、运算高效,整个框架的代码实现超过了四万行。
随后,作者将Squirrel框架在真实的数据库管理系统上测试。主要关注以下三个问题:
是否能检测出内存漏洞?是否超过了SOTA的测试工具?语言正确性和覆盖率反馈在测试中的作用如何?
由此,将实验分为三个部分:语法正确性测试、语义正确性测试和性能测试。
在语法正确性和语义正确性测试中,作者使用Sqirrel、AFL、SQLsmith、QSYM、Angora和GRIMOIRE等六个工具对SQLite和MySQL进行测试,并比较了它们的测试效果。作者使用了10个已知的语法错误和缺陷来评估这些工具的测试效果,并计算了它们的错误检测率和测试时间。
在性能测试中,作者使用了Sqirrel、AFL、SQLsmith、QSYM、Angora和GRIMOIRE等六个工具对SQLite和MySQL进行测试,并比较了它们的测试效果。作者使用了10个已知的性能问题来评估这些工具的测试效果,并计算了它们的测试时间和覆盖率。
Sqirrel在40天内发现了四个流行的DBMSs上的63个内存错误问题,其中包括51个SQLite错误、7个MySQL错误和5个MariaDB错误。综合实验各项指标,其结果表明Sqirrel在语法正确性测试、语义正确性测试和性能测试中都表现出色,能够有效地检测出各种类型的错误和缺陷,并且具有较高的测试效率和覆盖率。
最后,对文章所做的研究不足之处及未来可以继续开展工作总结如下:
提高测试效率:本文中提到Sqirrel的测试效率相对较低,需要较长的时间来生成测试用例。结合我自身复现代码的过程也印证了这一点。因此,未来的工作可以探索如何提高测试效率,例如使用并行化技术或者优化测试用例生成算法。
提高测试覆盖率:本文中Sqirrel的测试覆盖率仍有提升空间。未来的工作可以探索如何提高测试覆盖率,例如使用符号执行技术或者结合其他测试方法。
改进测试用例生成算法:本文中使用的测试用例生成算法可以生成语法正确的测试用例,但是无法保证语义正确。未来的工作可以探索如何改进测试用例生成算法,以提高测试用例的语义正确性。
扩展到其他类型的漏洞:本文中Sqirrel主要用于检测内存损坏漏洞,而数据库管理系统中存在的漏洞多种多样,面对的外部威胁更是防不胜防。未来的工作可以探索如何将Squirrel扩展到检测其他类型的漏洞,例如SQL注入漏洞或者逻辑漏洞等。